
2-ysyThread-如何设计动态线程池?
如何设计动态线程池
聚焦线程池问题
线程池的问题与业务规模无关——只要你用线程池,就势必会遇到这几道问题
线程池随意
new,资源失控 —— 因为 缺乏统一注册表 —— 通过 线程池注册中心 + 统一管控参数难估算、只能重发 —— 因为 静态配置 & 无监控 —— 通过 运行中热刷新 + 实时指标采集
队列堵塞 / 拒绝策略“黑盒” —— 因为 无告警 & 无追踪—— 通过 三重告警触发器 (活跃度 / 队列 / 拒绝)
下线时任务丢失 —— 因为 线程池生命周期缺口 —— 通过 优雅关闭 Hook
线程池问题解决思路
1. 线程池资源管理 —— Nacos
把线程池的声明全部收敛到配置中心:先在配置中心登记,再由应用按需装配
项目统一约定:如需新增线程池,必须先在配置中心完成登记,再由应用自动装配,确保规范一致、可追溯。
2. 线程池参数动态变更
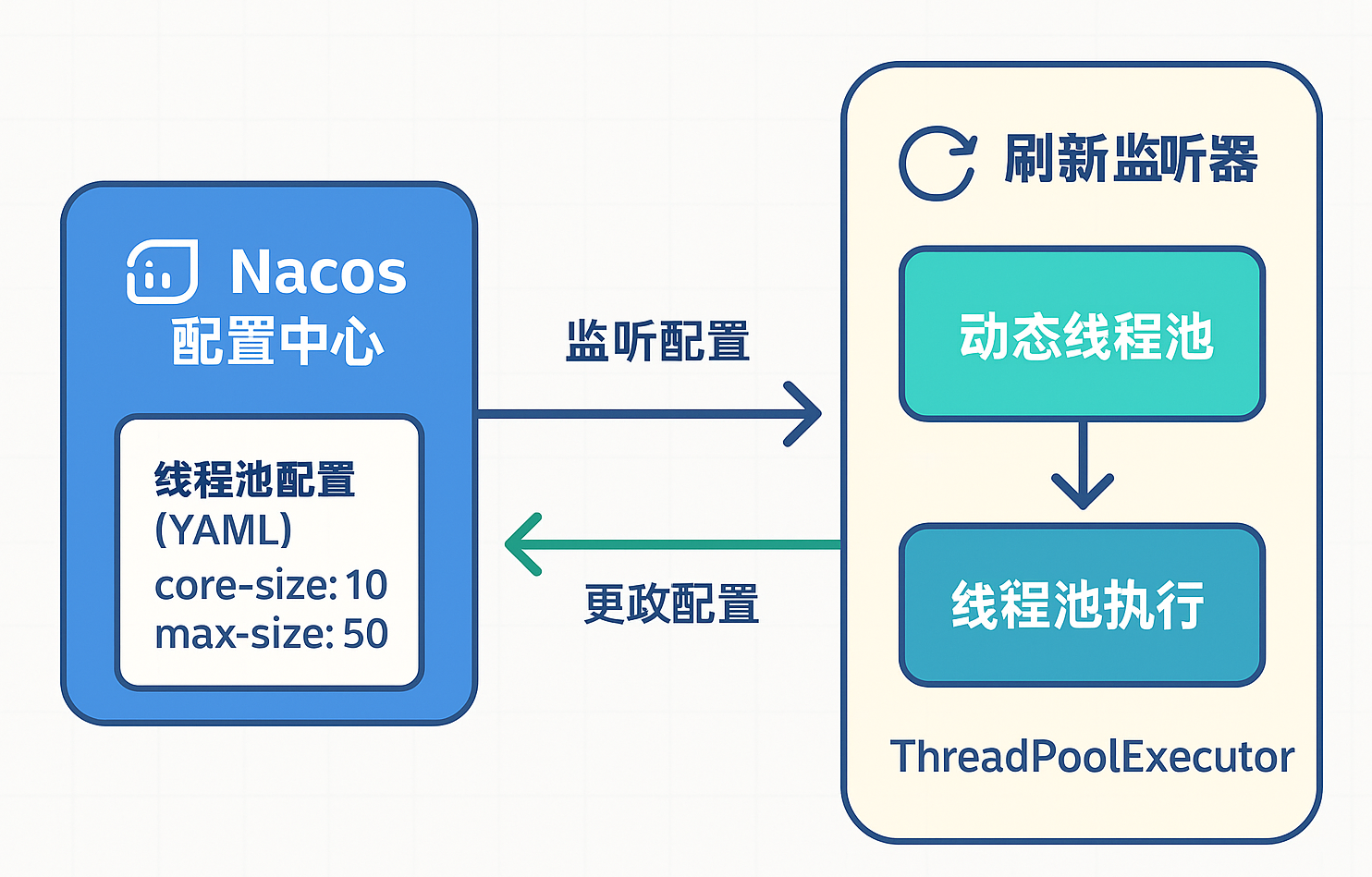
Nacos既是配置中心也是注册中心。只要把线程池参数集中存放在Nacos,Spring Boot客户端即可持续监听。当检测到线程池配置有更新时,立即拉取最新参数并触发动态线程池刷新流程,做到配置一改、线上秒生效
看起来只是“监听-刷新”,真正落地却有两座大山:
YAML → Java映射:Spring Boot监听器拿到的仅是一段纯YAML字符串,如何优雅地反序列化成线程池配置对象?多配置中心的代码复用:作为通用组件,我们势必要同时适配 N 个配置中心。怎样抽象公共逻辑,既避免
if-else轰炸,又能随时plug-in新配置中心?
3. 运行时通知告警
关注的维度
关注【活跃度、队列负载、拒绝异常】3 个维度
活跃度:
activeCount / maximumPoolSize连续高于阈值(默认 80%),说明 线程资源已逼近瓶颈,需扩容或对入口流量做限流队列负载:
queueSize / queueCapacity超过阈值,说明 排队任务激增,处理能力被入口流量压制,易引发大面积超时拒绝异常:监控到新的
RejectedExecutionException,说明 线程池已无法接收新任务,属于阻断场景,应立刻介入
实现思路
- 【活跃度、队列负载】的监控规则较为简单,通过 定时任务扫描 即可实现。不过需要注意的是,定时任务的执行间隔需合理设置:过短 会因监控
API加锁导致与线程池其他操作竞争锁资源,过长 则可能错过重要的告警时机。在充分权衡后,默认将扫描间隔设置为 5 秒 - 【拒绝策略】的告警机制是通过 动态代理 实现的:每当线程池触发一次拒绝策略,对应的计数器就自增一次。在 定时任务 扫描时,会比较当前的拒绝次数与上次扫描记录的次数,如果 出现新增,则立即触发告警
为什么【告警机制】使用 动态代理 机制?
因为:
JDK原生的拒绝策略(RejectedExecutionHandler)接口主要有 4 种实现(Abort,CallerRuns等)。如果我们想统计拒绝次数,最笨的方法是:写一个MyAbortPolicy继承AbortPolicy,重写方法,加个计数器;写一个MyCallerRunsPolicy继承CallerRunsPolicy,重写方法,加个计数器;……侵入性太强,且不可扩展- 利用
JDK动态代理,可以在不修改原有拒绝策略代码的情况下,给任意拒绝策略“穿上一层马甲”,这层马甲负责计数
4. 线程池运行监控
- 线程池监控并非锦上添花,而是高并发应用的核心基础设施之一
- 明确线程池监控的核心需求
- 活跃线程数:判断线程池是否逼近性能瓶颈
- 队列负载:识别任务堆积风险
- 拒绝策略触发:及时发现线程池溢出异常
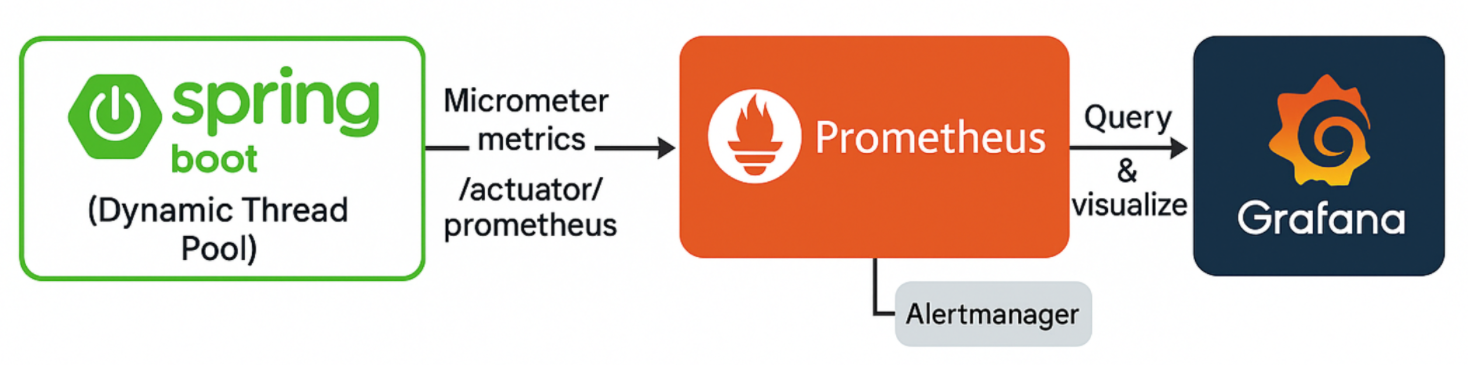
Prometheus + Grafana是一套成熟、易用且稳定的组合方案,广泛应用于各类系统的指标监控场景。选择它们作为线程池监控的基础,主要基于以下考虑:
Prometheus采用 主动拉取(Pull)模型,能够定时抓取线程池的核心运行指标,如【活跃线程数、队列长度、拒绝次数】等。同时内置时序数据库,部署简单、性能可靠,已在大量场景中验证其稳定性Grafana与Prometheus深度集成,配置数据源即可使用,支持丰富的图表类型和灵活的仪表盘定制,能够清晰展示线程池的运行状态与历史趋势,便于问题定位与运维决策- 通过
Prometheus采集与存储指标,配合Grafana的可视化能力,构建完整的线程池监控体系,既适用于开发调试,也适用于生产环境的持续观测
5. 优雅关闭防任务丢失
- 如果仅按
ThreadPoolExecutor直接创建并使用线程池,而 没有补充任何优雅停机逻辑,一旦应用关闭或重启,线程池中尚未处理完的任务必然丢失。原因在于:应用停机流程里缺少“兜底”步骤——先检测线程池是否仍有待执行任务,再在设定的宽限期内等待其完成 - 这种兜底通常依赖
Shutdown Hook(钩子):当进程收到停止信号时,系统会调用预先注册的Hook,在真正退出前执行自定义清理代码。若未注册Hook,线程池会被立即终止,残余任务也随之丢弃
什么是 Hook(钩子)
Hook(钩子) 是一个编程术语,可以把它理解为 临终关怀机制**没有 **
Shutdown Hook:老板突然喊“关门”,保安直接把电闸拉了,正在吃饭的顾客吃到一半被赶走,厨师正在炒的菜直接倒掉。结果:一片狼藉,数据丢失有了
Shutdown Hook:老板喊“准备关门”。这时候会触发一个流程(Hook):不再接待新客人,但等待已经坐下的客人吃完,厨师把锅里的菜炒完装盘,打扫卫生,最后再拉电闸
在
Java中,Shutdown Hook是一个线程,可以通过代码提前把这个线程“挂”在JVM(Java虚拟机)上。当JVM准备关闭时,它不会立即停止,而是会先去执行这些挂上去的线程
Hook 在应用层面的分类
Hook在当前应用层面可以分为三类:- 操作系统信号:
SIGTERM/ SIGINT / SIGKILL来触发 JVM ShutdownHook:Runtime.getRuntime().addShutdownHook()来触发- 框架 / 容器
Hook:Spring、Tomcat、Netty等框架生命周期回调来触发
- 操作系统信号:
- 这三层
Hook自上而下串联:SIGTERM→JVM捕获并触发ShutdownHook→Spring发布ContextClosedEvent→Bean销毁回调
我如何设计的
利用 Spring Bean 级 Hook 完成线程池的任务检测与等待:收到停机信号后,先检查线程池中是否仍有未完成任务,再在设定的宽限期内调用 awaitTermination,确保任务尽量执行完毕后再退出
基础组件开发推荐方案
Starter能让Spring Boot项目“一键启用”,但它只服务于Boot。我想覆盖的不止是Boot应用,还包括普通Spring项目,甚至纯Java程序。如果把所有功能都塞进Starter,非Boot场景根本没法无缝接入- 如果你在非
Boot环境里硬拉一个Starter,然后自己写启动逻辑去“模拟”自动装配,会踩两大坑:- 其一,
Boot独有的条件注解和配置绑定在普通Spring根本解析不了; - 其二,
Starter写得越重,耦合就越深,想自定义启动点几乎没有空间
- 其一,
- 最好的例子就是
XXL-Job,它只给了一个core包,任何项目只要new一下XxlJobSpringExecutor,注册成Bean就能用。如果XXL-Job将复杂初始化逻辑(假设有)当初全都写在Starter里,非Boot项目就得二次开发才能接入
| 项目类型 | 应该引入的模块 |
|---|---|
| 纯 Java / 非 Spring | ysythread-core |
| Spring (非 Boot) | ysythread-spring |
| Spring Boot | ysythread-starter(很薄,仅做自动装配) |
1 | . |
在
Hippo4j的实践中,深刻体会到“深度绑定Spring Boot”带来的痛点:版本升级一动就牵一发而动全身,依赖矩阵异常复杂。因此,只依赖Spring(或者不强依赖)而非Spring Boot——第三方依赖越少,架构就越纯净、可维护性也越高。





