
11-ysyThread-动态线程池监控
动态线程池监控
仅靠“事发时的告警”远远不够。没有监控,开发人员排查问题只能靠猜,做性能调优也没底
所以强调,线程池监控不是只为了报警,它更重要的价值在于
- 辅助定位问题 :出故障时,能看到是线程数打满了,还是队列堆积了
- 支持容量规划 :通过长期趋势判断线程池配置是否合理
- 洞察系统瓶颈 :比如是否存在某些任务执行时间异常拉长,影响整体调度效率
本地日志监控实现
1. 定时任务调度机制
本地日志监控的核心是定时任务调度机制
2. 本地日志输出实现
本地日志监控的实现相对简单,但需要确保 日志格式的规范性和可读性:
1 | private void logMonitor(ThreadPoolRuntimeInfo runtimeInfo) { |
3. 设计模式应用
对于监控采集类型的判断逻辑,其实还有优化空间
如果后续框架有计划支持更多存储策略(比如 ElasticSearch 等),就可以引入策略模式 ,实现按需切换
但如果当前只打算用一种或两种固定方式,那用一个简单工厂模式 来创建也更轻量,足够应对,扩展成本也低
当前实现方案中,通过配置参数collectType来决定使用哪种监控策略
- log策略 :将监控信息输出到本地日志
- micrometer策略 :将监控指标发送到
Micrometer监控系统
1 | // 根据配置的采集类型分发处理 |
运行时信息采集优化
1 | public class ThreadPoolRuntimeInfo { |
Micrometer监控实现(最佳)
虽然日志监控在问题排查时很有用,但在生产环境中,我们更需要的是专业的监控体系集成
想象一下这样的场景:
凌晨 2 点,你的手机突然响起告警铃声——
Grafana监控面板显示某个核心业务线程池的活跃线程数持续飙升,队列堆积严重。你立即打开监控大盘,通过时间序列图表清晰地看到:从 1:30 开始,该线程池的active.size指标从正常的 5-10 逐步攀升到 50,同时queue.size也从 0 增长到 500+。更关键的是,通过多维度标签筛选,你快速定位到是order-service应用的payment-processor线程池出现了异常
这就是专业监控系统的威力,相比本地日志监控,Micrometer指标监控 的最大优势在于它能直接对接 Prometheus、Grafana 这些专业监控工具
要实现一个高质量的
Micrometer监控集成,需要考虑的细节远比想象中复杂
- 如何设计合理的 指标命名规范?
- 怎样通过 标签体系 实现 多维度监控?
- 如何优化指标注册性能,避免重复创建?
- 怎样确保监控数据的 准确性和一致性?
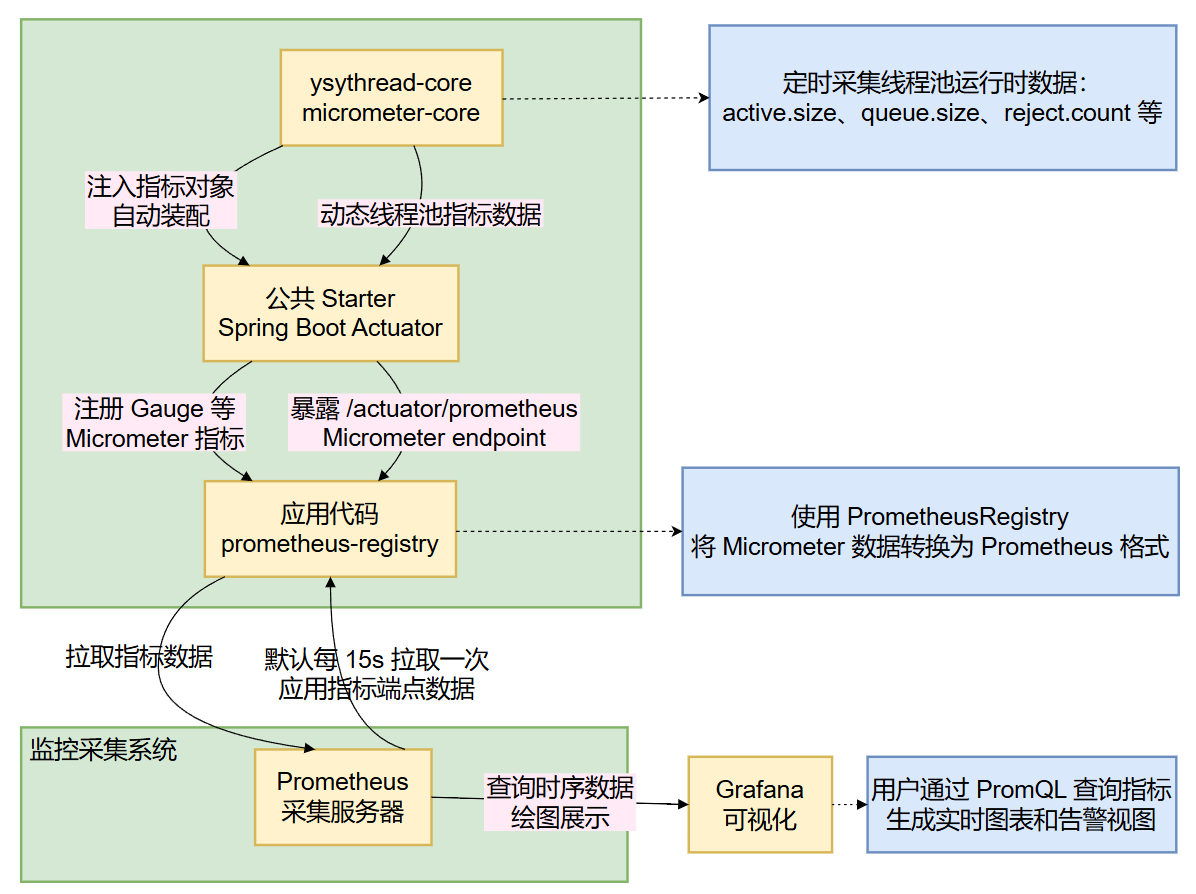
Micrometer 依赖体系解析
1 | <!-- ysythread-core 包中 --> |
micrometer-core
是整个监控体系的基石 ,提供了 Micrometer 的核心抽象层。它最重要的作用是 定义了统一的指标 API,让我们的框架代码不用关心底层到底用的是 Prometheus 还是 InfluxDB
spring-boot-starter-actuator
Actuator 的作用远不止暴露几个 HTTP 端点那么简单,它是 Spring Boot 应用生产就绪 的核心组件
在监控方面,
Actuator主要做了这几件事:
- 自动配置MeterRegistry :根据
classpath中的依赖自动创建对应的Registry Bean- 指标收集器注册 :自动注册
JVM、系统、Web等各种内置指标收集器- 端点暴露 :提供
/actuator/metrics、/actuator/prometheus等端点- 安全控制 :支持对监控端点的访问控制和权限管理
micrometer-registry-prometheus
这个依赖是监控后端的具体实现 ,它的作用是将 Micrometer 的通用指标格式转换为 Prometheus 特有的格式
应用层配置要求
除了依赖配置外,应用代码还需要在 application.yml 中添加相应的配置来启用 Prometheus 端点
1 | management: |
分层设计的优势与实践价值
架构灵活性 :
想象一个场景:你们公司最初用的是 Prometheus + Grafana 的监控方案,后来因为成本或技术栈的原因,决定切换到阿里云的 ARMS 或者腾讯云的监控服务。
在传统的设计中,这可能意味着要修改框架代码、重新测试、重新发布。但在我们的分层设计中,只需要:
1 | <!-- 原来的依赖 --> |
框架代码一行都不用改,因为它只依赖 micrometer-core 的抽象接口
指标采集与注册实现
1. Micrometer 监控核心实现
1 | private void micrometerMonitor(ThreadPoolRuntimeInfo runtimeInfo) { |
2. 指标命名规范设计
1 | private static final String METRIC_NAME_PREFIX = "dynamic.thread-pool"; |
多维度标签体系设计
标签(Tag)是 Micrometer 监控的核心特性,通过标签可以实现多维度的数据切片和聚合
1 | private static final String DYNAMIC_THREAD_POOL_ID_TAG = METRIC_NAME_PREFIX + ".id"; |
缓存优化与性能考量
1. 缓存机制设计
为了避免重复创建 ThreadPoolRuntimeInfo 对象,我们引入了缓存机制:
1 | private Map<String, ThreadPoolRuntimeInfo> micrometerMonitorCache; |
2. 无缓存问题
在 Micrometer 中,Metrics.gauge() 方法会将传入的对象与 Gauge 指标绑定。如果每次监控都传入新的 ThreadPoolRuntimeInfo 对象,就会导致:
- 重复注册问题 :相同名称的
Gauge会不断注册新的对象引用 - 内存泄漏 :旧的
Gauge对象无法被正确清理 - 数据采集异常 :
Prometheus采集时可能返回NaN值
通过缓存机制,我们确保:
- 第一次监控时,将
ThreadPoolRuntimeInfo对象存入缓存,并注册Gauge指标。- 后续监控时,只更新缓存中对象的属性值,不改变对象引用。
Gauge指标 始终指向同一个对象,能够正确获取最新的监控数据
Gauge 指标注册优化
Micrometer 的 Metrics.gauge() 方法有个很贴心的设计:多次注册同名指标不会重复创建
虽然会执行指标注册代码,但实际上只有第一次会真正创建 Gauge 对象,后续调用都会复用已有的指标。
而且 Gauge 会持有对象引用来自动跟踪值变化,当对象被 GC 回收时,对应的 Gauge 也会被清理,不用担心内存泄漏问题





